


Many teams invest in data science with big expectations. They hire skilled people, choose modern tools, and still struggle to see results. In most cases, the problem is not the models or the math. The real issue is much simpler: “The data foundation is weak.”
This is where the confusion between Data Science and Data Engineering begins. These two roles are closely connected, but they are not the same. Understanding the difference is important for teams, leaders, and businesses that want data to create real value.
The Data Lifecycle: Where Each Role Fits
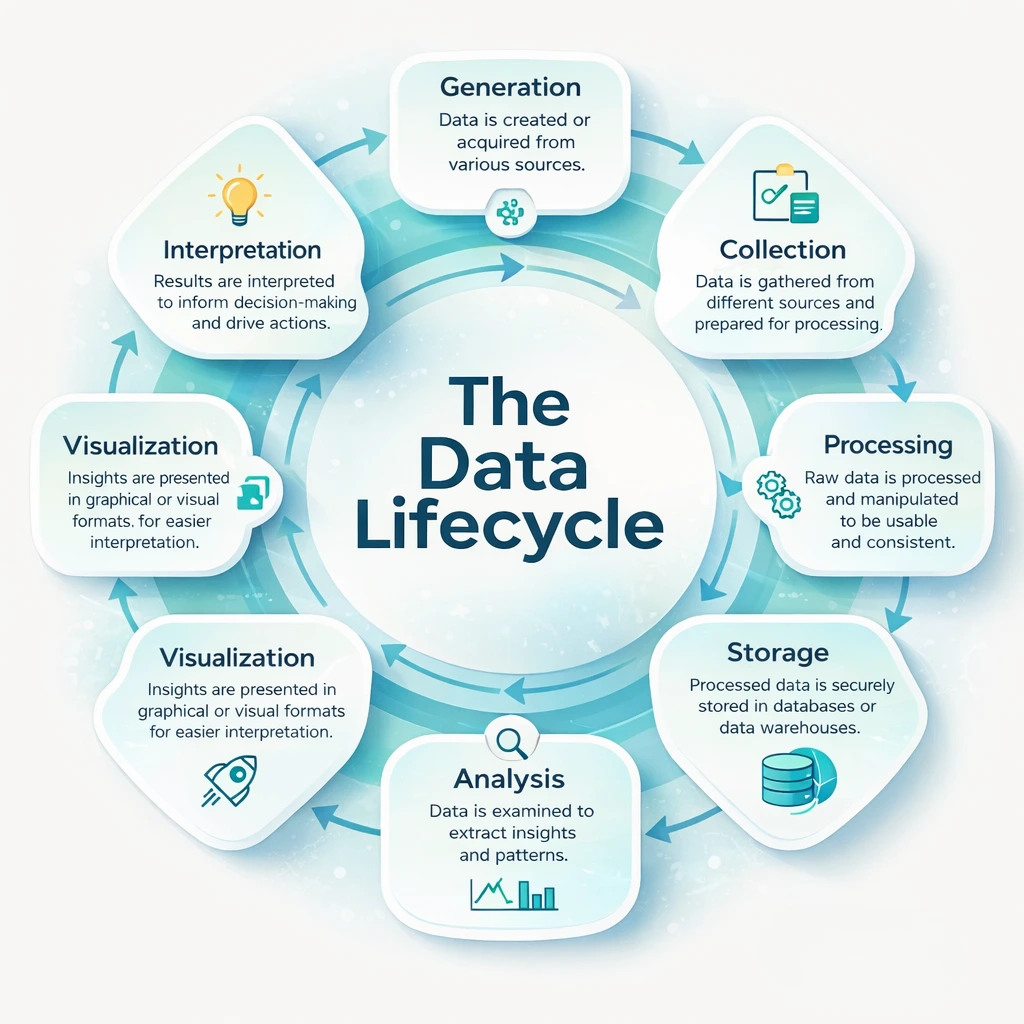
Before comparing Data Science and Data Engineering, it helps to understand how data actually moves inside a company. Data does not magically appear in dashboards or models. It goes through several steps before it becomes useful.
In most organizations, the data lifecycle looks like this:
- Data is created
Data comes from many places such as websites, mobile apps, payment systems, customer tools, sensors, and internal software.
- Data is collected and moved
This raw data is pulled from different systems and transferred into a central location.
- Data is cleaned and stored
Errors are fixed, formats are standardized, and data is stored in warehouses or data lakes so it can be reused.
- Data is analyzed and modeled
Patterns are explored, trends are identified, and predictive models are built.
- Insights are shared with the business
Results are turned into reports, dashboards, forecasts, or recommendations that teams can act on.
This is where the difference between roles becomes clear.
- Data Engineering is responsible for steps one to three. The focus is on moving data reliably, keeping it clean, and making sure it is always available.
- Data Science works mainly in steps four and five. The focus is on learning from the data and turning it into insights that support decisions.
If data is missing, inconsistent, or delayed in the early steps, analysis becomes slow or misleading later on. Strong Data Engineering creates the foundation. Data Science builds value on top of it. This dependency is the reason these roles are closely connected and cannot succeed in isolation.
What is Data Engineering?
Data Engineering is the work that happens before any analysis or modeling can begin. It focuses on building a strong and reliable data foundation that the entire organization can trust.
A Data Engineer ensures that data is:
- Collected correctly from different systems
- Clean, accurate, and consistent
- Easy for teams to access and use
- Able to scale as data volume and business needs grow
Instead of working with insights directly, Data Engineers work behind the scenes. Their job is to make sure data flows smoothly from source systems to storage layers without breaking, duplicating, or losing meaning along the way.
Typical responsibilities include:
- Building automated data pipelines that move data continuously
- Integrating data from multiple sources like applications, databases, and external tools
- Cleaning, validating, and standardizing data to reduce errors
- Managing data warehouses or data lakes so data stays organized
- Ensuring data is delivered on time and stays reliable as usage increases
The goal of Data Engineering may sound critical but it is pretty simple. You just have to create data that people can rely on without questioning its accuracy or freshness.
When this foundation is missing, teams spend most of their time fixing data issues, rewriting queries, or double-checking numbers. Strong Data Engineering removes this friction and allows analysts, scientists, and business teams to focus on creating insights instead of repairing data.
What Is Data Science?
Data Science is about turning data into understanding that people can act on. It focuses on answering questions, explaining what is happening, and predicting what might happen next.
A Data Scientist works with data to uncover meaning, not just numbers. The goal is to help teams make better decisions by using evidence instead of guesses.
A Data Scientist uses data to:
- Discover patterns hidden in large datasets
- Explain trends and behavior over time
- Predict future outcomes based on past data
- Support business decisions with clear insights
This work often starts with curiosity. A question is asked, and data is explored to find reliable answers.
Typical responsibilities include:
- Exploring and analyzing data to understand its structure and quality
- Creating statistical models to explain relationships and trends
- Building machine learning models for prediction or classification
- Running experiments to test ideas and assumptions
- Translating technical results into insights that business teams understand
The value of Data Science does not come from complex models alone. It comes from making insights clear, useful, and actionable.
Data Science works best when data is clean, complete, and consistent. When data is messy or unreliable, even the best models produce weak results. This is why strong Data Engineering is so important. It provides the stable foundation that allows Data Science to focus on insight creation instead of data cleanup.
Data Science vs Data Engineering: The Key Differences

The table below highlights the core differences between Data Engineering and Data Science based on how each role contributes to real-world data projects. It focuses on purpose, responsibilities, and business impact.
| Area | Data Engineering | Data Science |
| Main focus | Data foundation | Insights and predictions |
| Type of work | Pipelines and infrastructure | Analysis and modeling |
| Data state | Raw to clean | Clean to meaningful |
| Business impact | Enables all data work | Drives decisions |
| Risk of failure | Data breaks or delays | Wrong or unusable insights |
| Dependency | Works independently | Depends on engineering |
How Data Engineering and Data Science Work Together in Practice
In real data projects, Data Engineering and Data Science do not operate in isolation. They work as part of a continuous loop, each role supporting and strengthening the other.
A typical workflow looks like this:
- A Data Engineer builds pipelines to collect and prepare data
- A Data Scientist explores the data to understand patterns and gaps
- Data quality issues or missing fields are identified
- The Data Engineer improves the pipelines and data structure
- The Data Scientist builds models and analysis
- Insights are shared with business teams
This cycle repeats as data grows and business needs evolve. When collaboration is weak, problems appear quickly. Data Scientists spend too much time cleaning data instead of analyzing it. Data Engineers create pipelines that are rarely used. Business teams lose confidence in reports and insights.
When collaboration is strong, work moves faster. Insights become more reliable. Data turns into a shared and trusted asset across the organization.
Real-World Example: Customer Churn Prediction
Consider a company trying to predict customer churn.
The Data Engineer starts by collecting data from product usage, billing systems, and customer support tools. This data is cleaned, combined, and stored in a central location so it stays accurate and up to date.
The Data Scientist then analyzes customer behavior, identifies patterns that signal churn, and builds a prediction model. These insights help marketing and sales teams take action before customers leave.
If Data Engineering is missing, the model relies on incomplete or outdated data. If Data Science is missing, clean data produces no direction. The real value comes from both roles working together toward the same business goal.
Read More: Is the Data Science Field Oversaturated?
What Should Businesses Prioritize First?
One of the most common and expensive mistakes companies make is investing in advanced analytics before building a strong data foundation. Excitement around artificial intelligence and machine learning often leads teams to skip essential groundwork.
The right priority depends on the stage of the business.
Early-Stage Companies
At this stage, the focus should usually be on Data Engineering.
Young companies often have scattered data across tools and platforms. Reports do not match, numbers are inconsistent, and manual work is common. Before thinking about predictive models, the business needs clean, structured, and reliable data. Without that foundation, advanced analysis creates confusion instead of clarity.
Growing Companies
As companies scale, both roles become important. Data Engineering stabilizes pipelines, improves data quality, and supports more users across departments. At the same time, Data Science begins to unlock deeper insights such as forecasting, customer behavior analysis, and performance optimization.
This is the stage where collaboration between the two roles becomes critical.
Mature Organizations
In mature companies, Data Engineering and Data Science function as one integrated system.
Data flows reliably across teams. Models are deployed into production. Insights directly influence product, marketing, operations, and strategy. Decision-making becomes faster and more confident because the foundation is already strong.
Many failed data initiatives share a similar pattern. The company invested in advanced analytics without fixing core data issues first. Strong infrastructure creates the environment where Data Science as a service can truly deliver value.
Data Science and Data Engineering: Better Together
This is not a competition between two roles. It is a partnership. Data Engineering builds the foundation. It ensures data is reliable, structured, and ready to use.
Data Science builds on that foundation. It transforms prepared data into insights and direction.
We can say, “One creates stability, the other creates strategy.”
When organizations understand this balance, data stops being a technical function and becomes a real business advantage. Strong foundations combined with meaningful insights lead to better decisions and measurable growth.
Build Data Systems You Can Trust
Data should make your work easier, not more confusing. At Hasan The Analyst, our goal is simple. Help you organize your data, clean it properly, and turn it into insights that actually support decisions. We focus on practical solutions that work in the real world.
If your reports do not match, your dashboards feel unreliable, or your analytics projects are not delivering results, you are not in danger; you require a good data system. Most problems start with structure, not tools.
Let’s build a data system you can rely on, grow with, and use confidently every day.
FAQ
What is the average salary of a Data Scientist in the United States?
In the United States, the average base salary ranges between $112,000 and $130,000. With bonuses and additional compensation, total pay often reaches $150,000 to $156,000. Entry-level roles start around $75,000, while senior AI-focused professionals can earn $200,000 or more.
What is the average salary of a Data Engineer in the United States?
In the United States, the average base salary typically falls between $107,000 and $125,000. Total compensation for mid-to-senior roles often reaches $130,000 to $140,000. Senior engineers can earn $160,000 to $250,000+, depending on experience, industry, and city.
Who gets paid more, a Data Scientist or a Data Engineer?
At entry level, Data Engineers often earn slightly more. At senior and AI-focused roles, Data Scientists may earn higher total compensation, especially in tech and finance companies.
Which role is more in demand?
Both are in strong demand. Data Engineering is consistently needed for infrastructure. Data Science demand grows in AI-driven companies focused on forecasting, automation, and advanced analytics.